前言
前几天用Stable Diffusion到做一个文字图片融合的示例,今天就使用 Stable Diffusion API 批量操作制作,使用文生图API把视频拆成一帧一帧的图片,把这些图片融入到Stable Diffusion生成的图片里面去。
自己的Stable Diffusion 部署在Linux系统上,每次开机都需要手动切用户使用shell脚本,想做一个开机自动启动的脚本
开机脚本
使用linux systemd 服务管理工具,我的系统版本是Ubuntu22.04,需要新建服务管理脚本,文件位置:/etc/systemd/system/webui.service,内容如下:
| |
1.注意使用正确的用户启动这个命令 ,我这里是koala9527
2.还要注意正确的Stable Diffusion 的启动目录,我这里使用的绝对路径,从根目录开始写的
3.注意我这里相对比上篇文章写的启动参数增加一个--api的选项,这里是启动API服务
使用一下命令使它重启自动启动并现在启动
| |

下载controlnet
上篇只下载了controlnet 扩展,这次需要安装它的模型
模型地址:https://huggingface.co/lllyasviel/ControlNet-v1-1
需要使用Git下载移动到相关目录:/*sd安装目录*/extensions/sd-webui-controlnet/models (体积比较大,耐心等待~)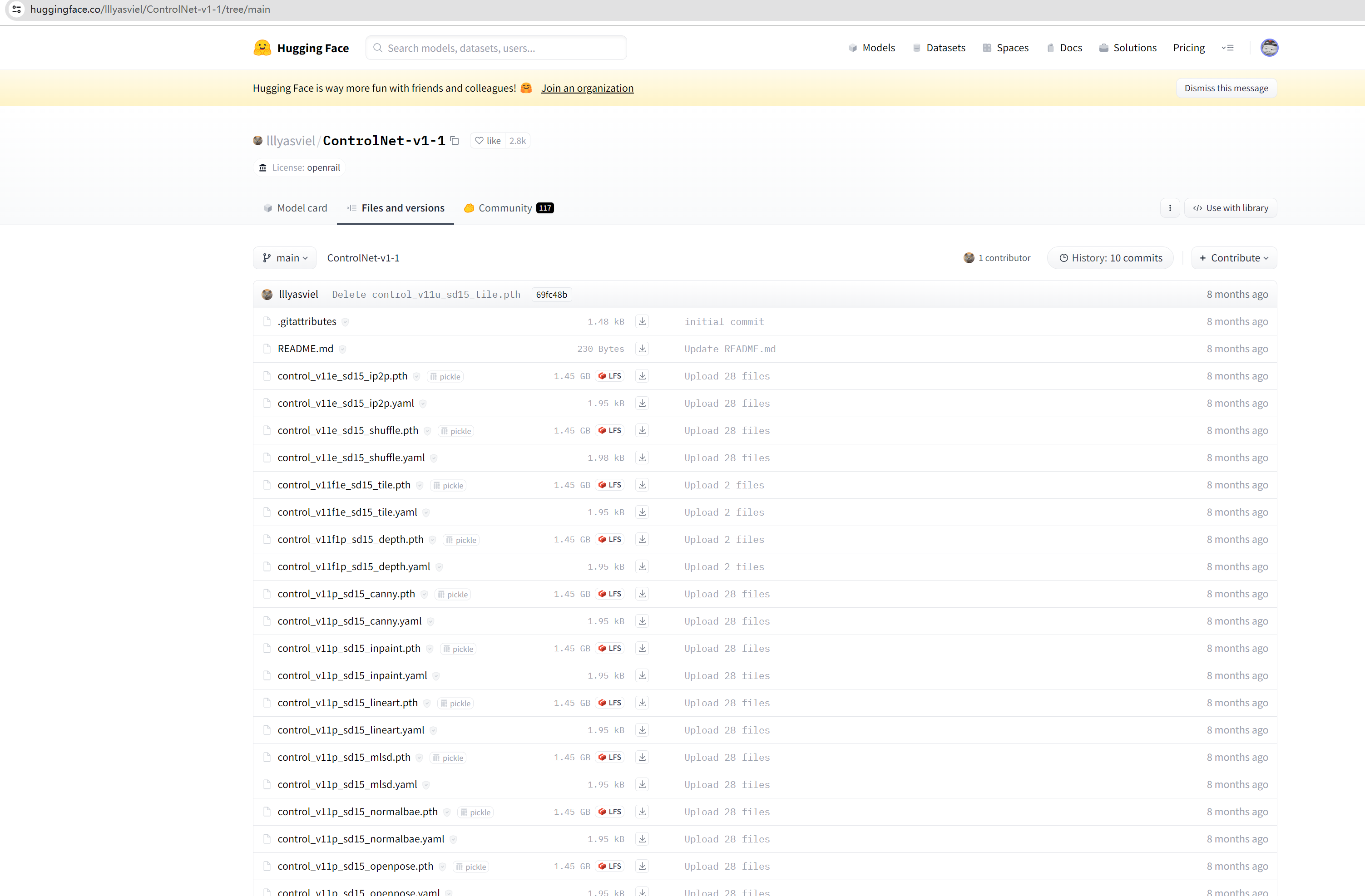 下载移动完成后效果:
下载移动完成后效果:

参考源码
没有官方文档,自己找了一些案例测试了很久,最后是按照这个项目完成了想要的结果
ControlNet API项目地址:
https://github.com/Mikubill/sd-webui-controlnet
API
刚在脚本启动的时候增加了一个参数:--api,开放了相关的API 接口,现在访问Stable Diffusion 的地址加上/api:
| |
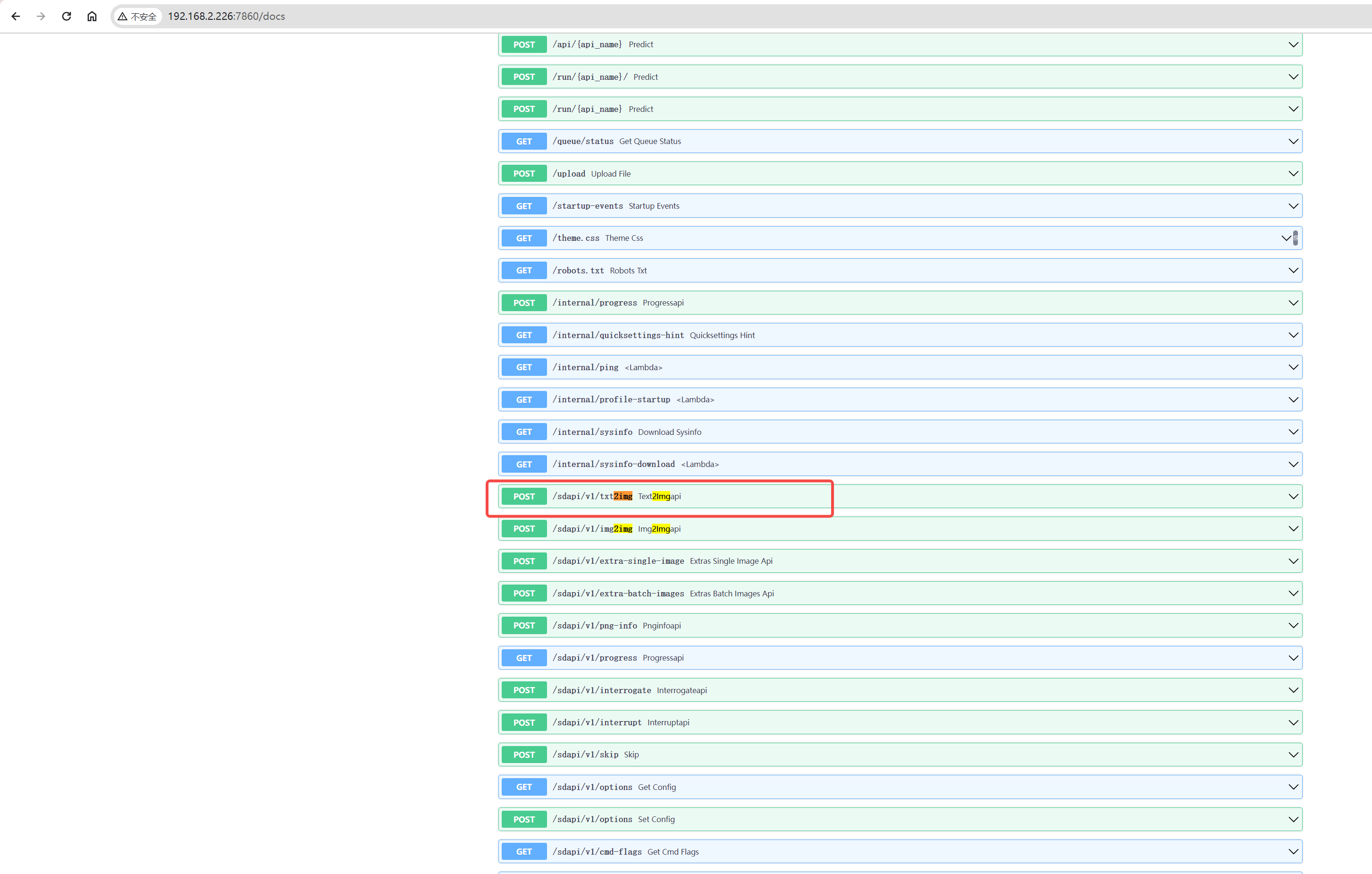
找到接口:sdapi/v1/txt2img
所以得到最终的请求接口:http://192.168.2.226:7860/sdapi/v1/txt2img
根据上篇文章的图片融合的功能构造的请求参数:
| |
封装功能Python函数
大概几个逻辑: 提前需要把视频手动拆解成图片。 然后代码功能就是把这些图片分别转base64 转入SD接口,然后请求API 得到图片base64数据存到本地
整个Python 脚本:
| |
在脚本目录下还有相关读取的文件夹,需要把融合的视频拆成一帧的文件夹为cxk ,通过融合过后保存的文件夹 需要提前新建:cxk_build 文件夹
测试
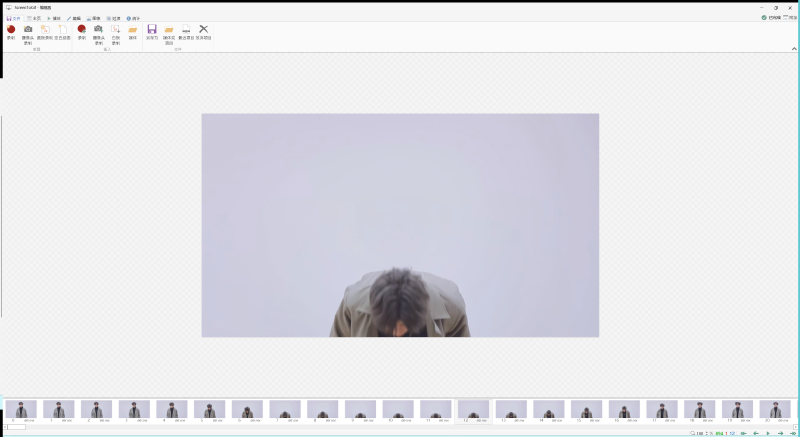
脚本运行完毕可以看到 cxk_build 文件夹生成了很多图片,我这里的视频是59秒,拆成一帧一帧的图片一共生成接近900张图片,使用的工具是ScreenToGIF,使用2070s生成一张15秒-16秒之间,粗略计算大概接近4个小时,非常耗电,哈哈 。
然后测试了几个发现去掉三分之一的帧数观感最好,保留每一帧的图片闪动很快看不清背景图,保留一半的图每一帧的展示时间少了看不清融入的图
效果(为了缩小gif缩小体积,画质差了很多):
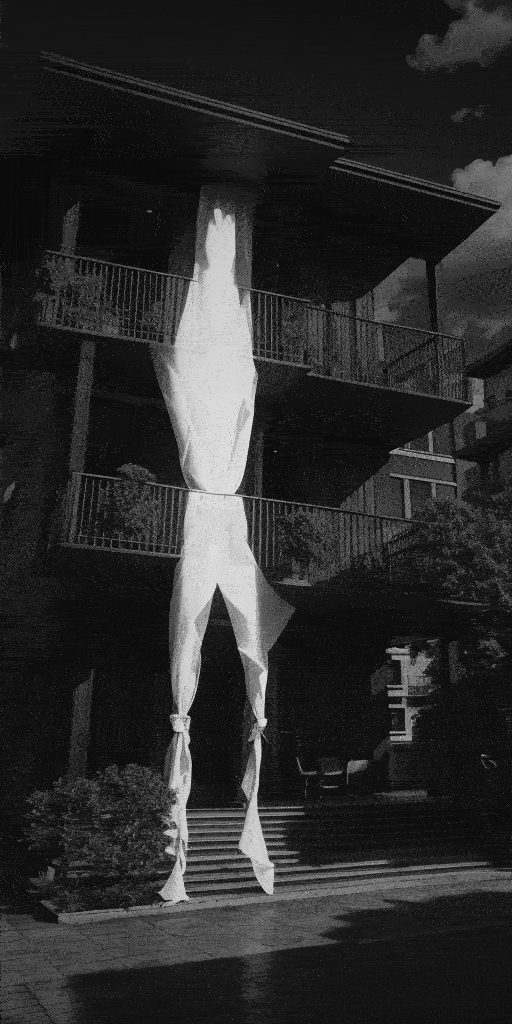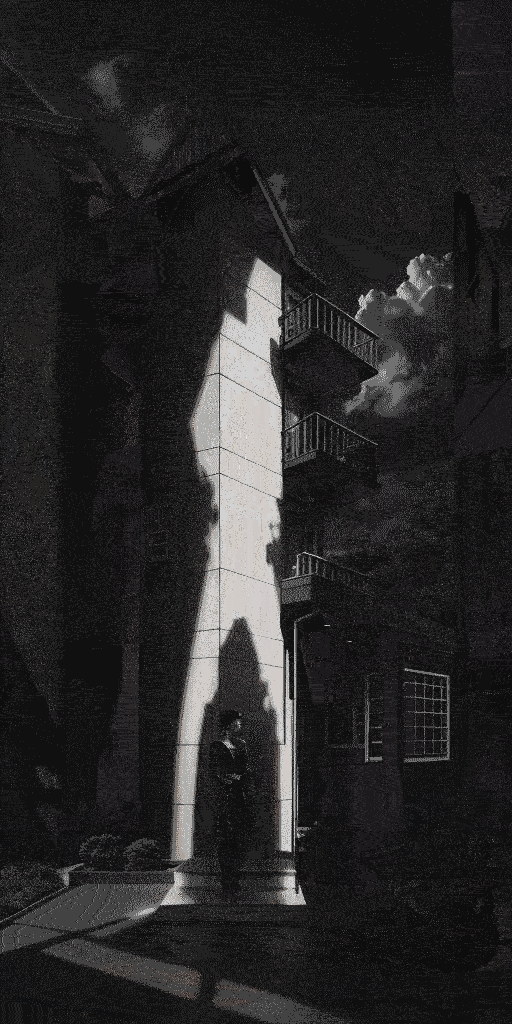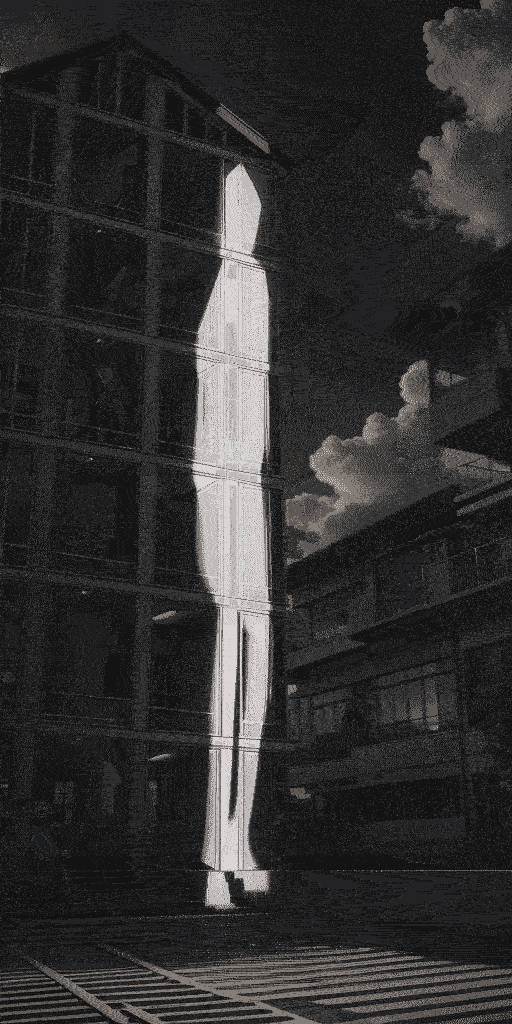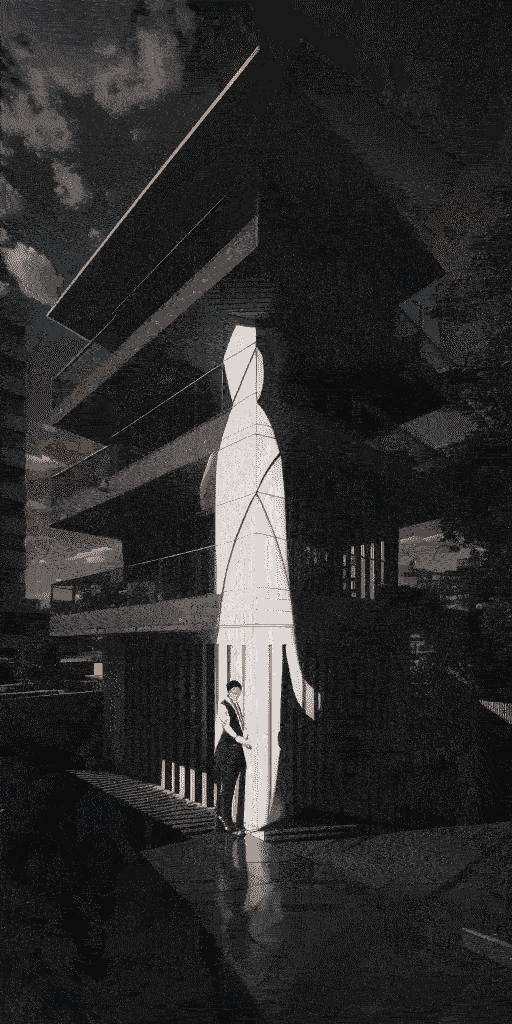
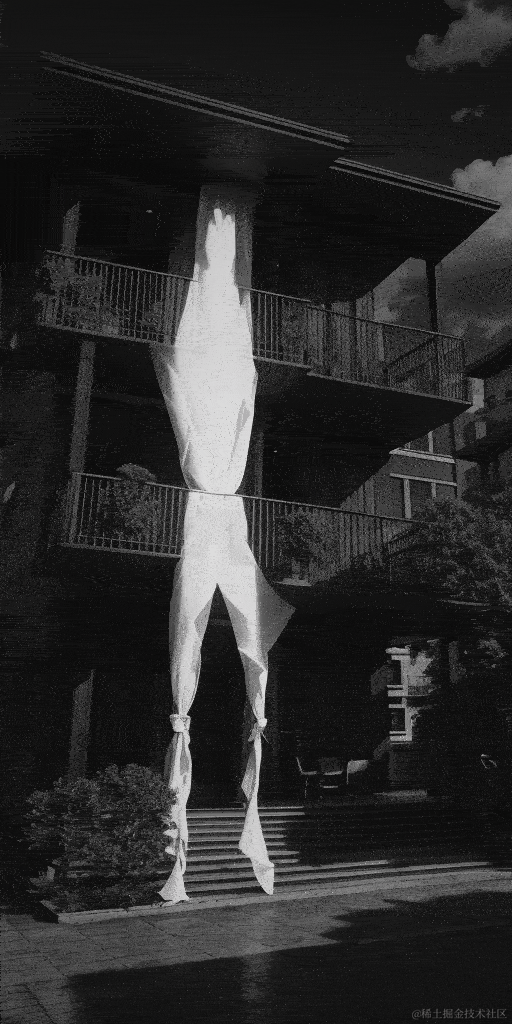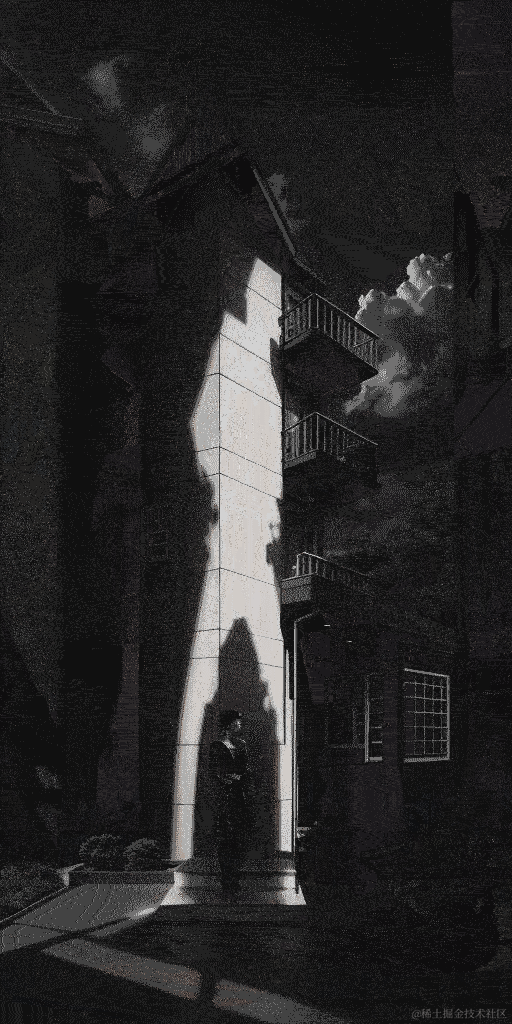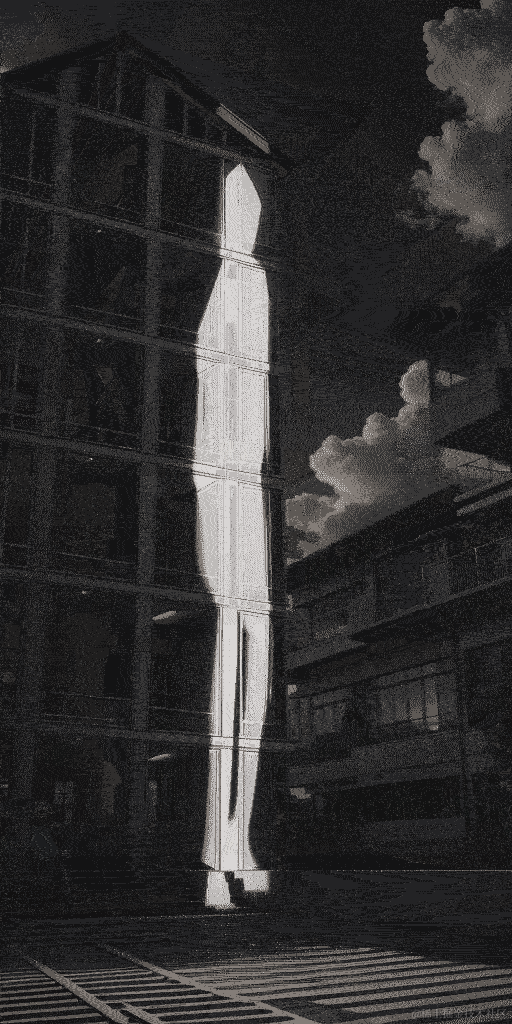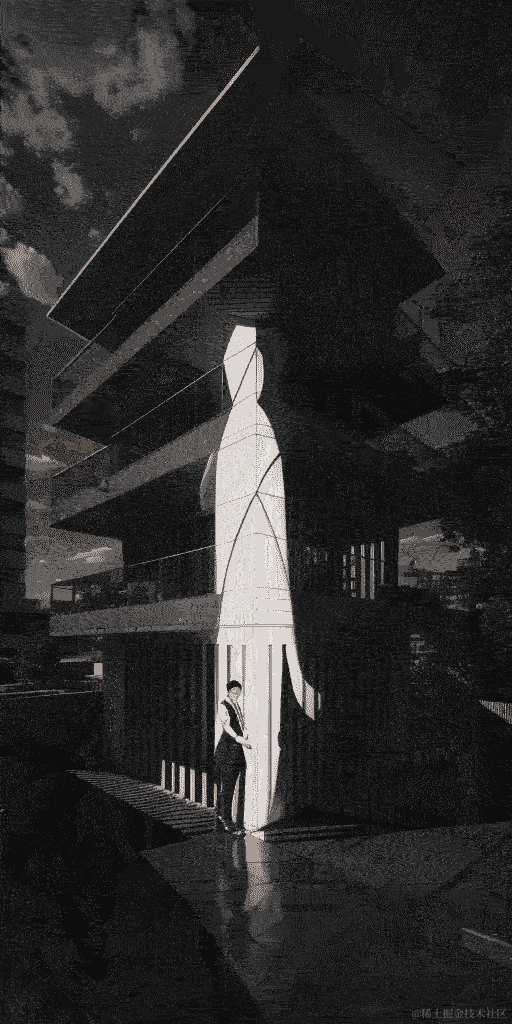
总结
其实使用 contolnet 脚本插件 LoopbackWave( https://github.com/FizzleDorf/Loopback-Wave-for-A1111-Webui) 以及Deforum(https://github.com/deforum-art/sd-webui-deforum) 插件可以达到比上图更好的更丝滑的视频动态转场效果,但是看起来操作比较复杂,原因是自己作为程序员更希望通过发挥自己的技能来做出一些意思的东西。 后面也会继续折腾,分享教程~