1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
import matplotlib.pyplot as plt
from collections import Counter
from pylab import mpl
begin_all_list = []
end_all_list = []
# 读取文件
with open('./100.txt','r') as f:
res = f.read()
for i in res.split('\n'):
one_data = i[5:-14]
# print(i,one_data)
begin,end = one_data[:10],one_data[10:] # 得到前区后区的字符串
bengin_list = [begin[i:i+2] for i in range(0, len(begin), 2)] # 前区切割成数组
end_list = [end[i:i+2] for i in range(0, len(end), 2)] # 后区切割成数组
print(i,one_data,begin,end,bengin_list,end_list)
begin_all_list += bengin_list # 搜集所有的前区号码
end_all_list +=end_list # 收集所有后区号码
begin_ball = range(1,36)
end_ball = range(1,13)
begin_ata_dict = {}
for i in begin_ball: # 遍历计算所有号码在前区号码的出现的次数
counter = begin_all_list.count('%02d' % i)
rate = round(counter/(5*100),0)
begin_ata_dict[str(i)] = {
"word":counter,
"count":counter
}
end_data_dict = {}
for i in end_ball: # 遍历计算所有号码在后区号码的出现的次数
counter = end_all_list.count('%02d' % i)
rate = round(counter/(2*100),2)
end_data_dict[str(i)] = {
"word":counter,
"count":counter
}
print(begin_ata_dict,end_data_dict)
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
count_list = [x['count'] for x in list(begin_ata_dict.values())]
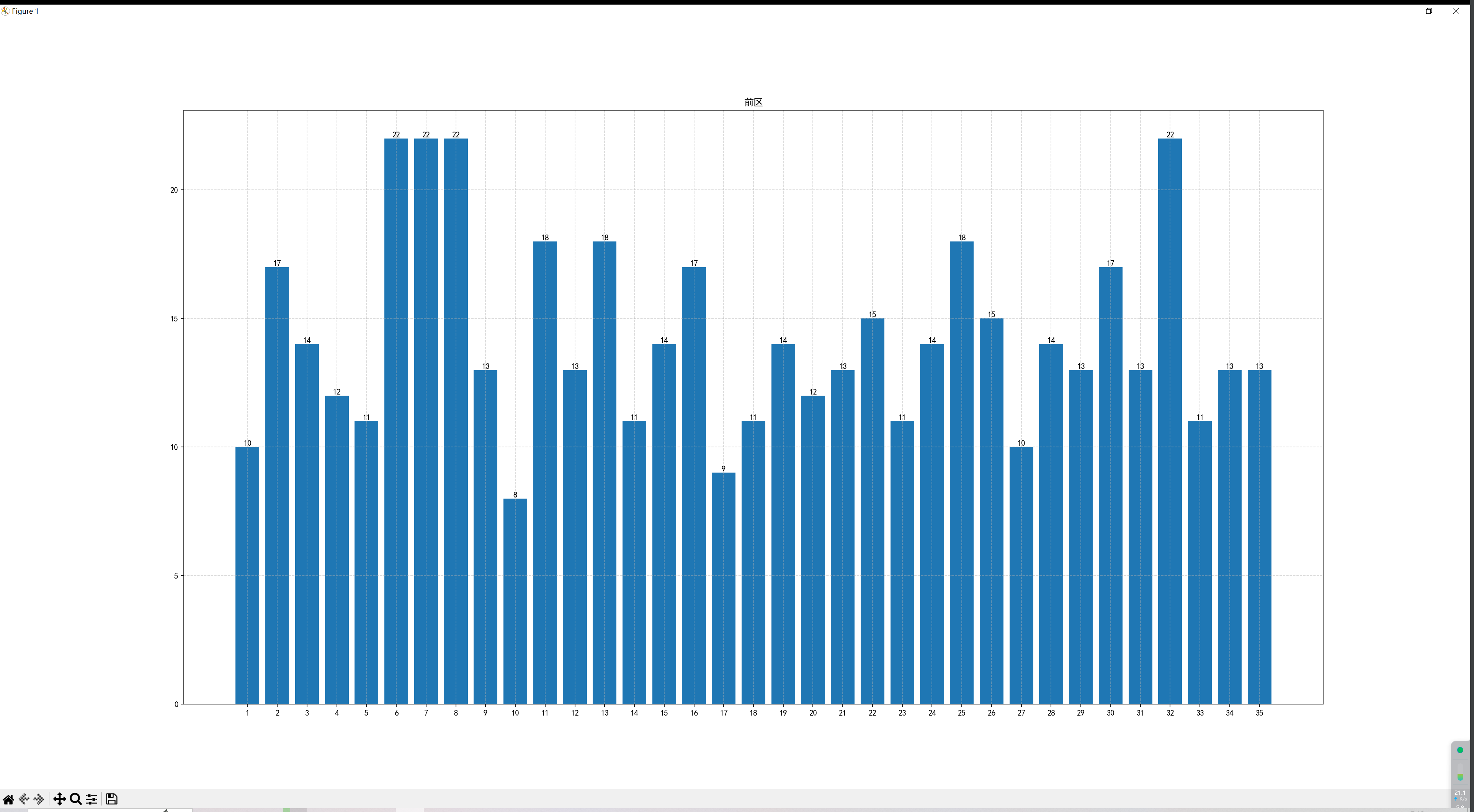
plt.title("前区")
plt.grid(ls="--", alpha=0.5)
print(list(begin_ata_dict.values()), list(begin_ata_dict.values()))
plt.bar(list(begin_ata_dict.keys()), count_list) # 画图指定X,Y轴内容
for i in range(len(count_list)):
word = list(begin_ata_dict.values())[i]['word']
print('wrod',word,list(begin_ata_dict.keys())[i])
plt.text(list(begin_ata_dict.keys())[i], word, word, va="bottom", ha="center") # 柱状图顶部文字
plt.show()
# 暂不能同时显示两张图片,取消注释后单独运行展示
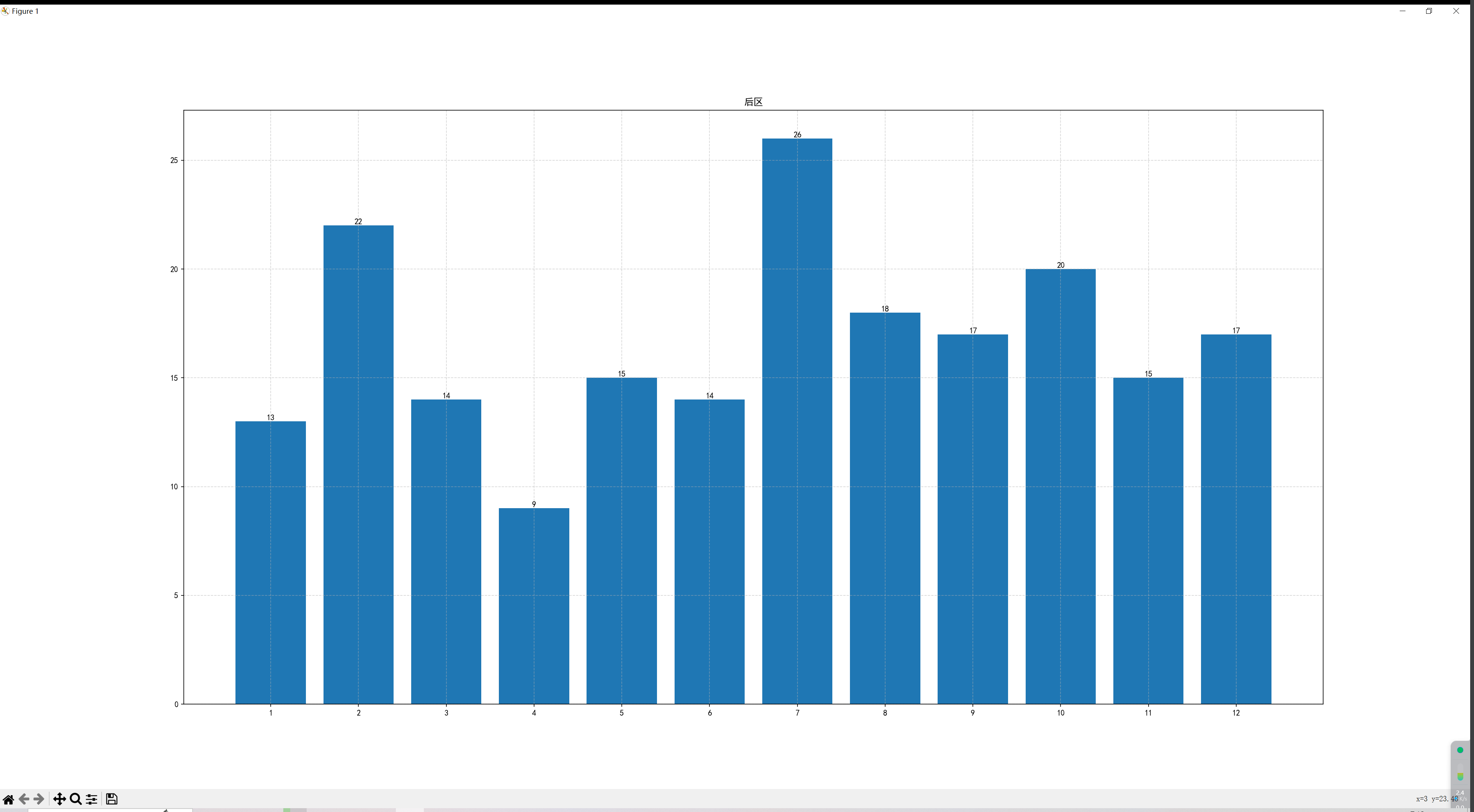
# count_list = [x['count'] for x in list(end_data_dict.values())]
# plt.title("后区")
# plt.grid(ls="--", alpha=0.5)
# print(list(end_data_dict.values()), list(end_data_dict.values()))
# plt.bar(list(end_data_dict.keys()), count_list)
# for i in range(len(count_list)):
# word = list(end_data_dict.values())[i]['word']
# print('wrod',word,list(end_data_dict.keys())[i])
# plt.text(list(end_data_dict.keys())[i], word, word, va="bottom", ha="center")
# plt.show()
|

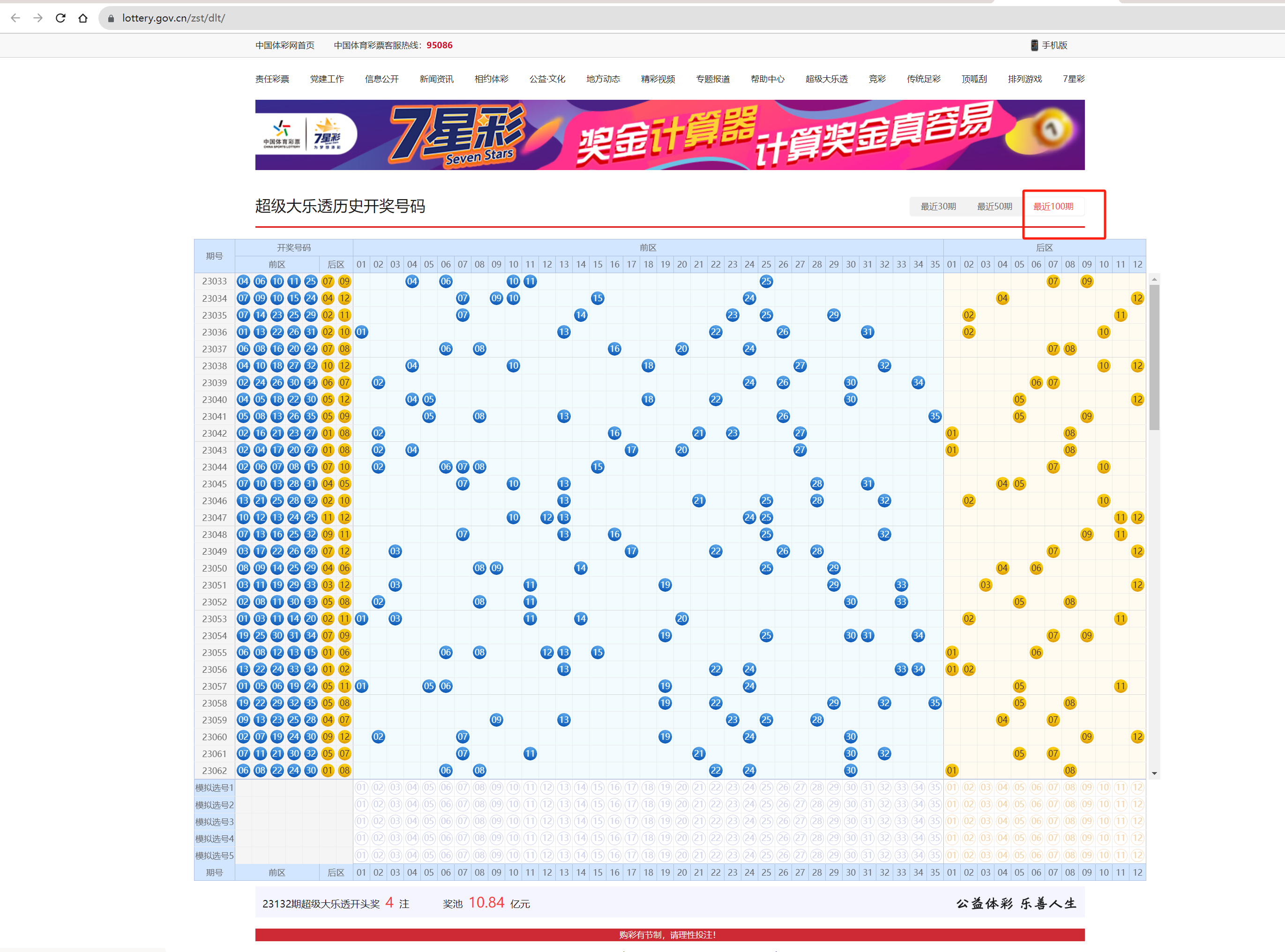 选择最近一百期,打开F12,找到任意一期其中一个数字的xpath:
选择最近一百期,打开F12,找到任意一期其中一个数字的xpath: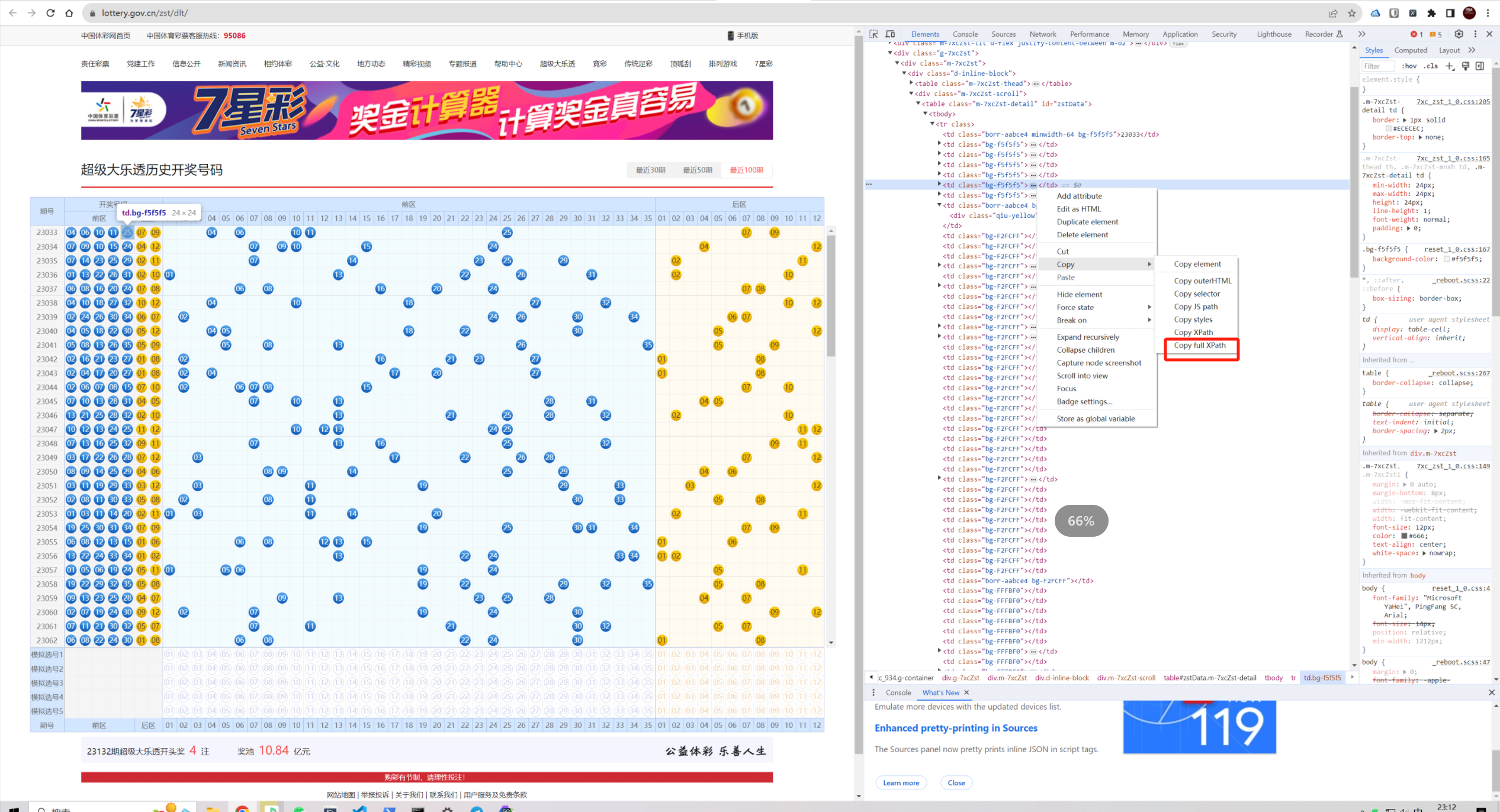 然后分析一下xpath,使用Chrome 插件:xpath-helper
然后分析一下xpath,使用Chrome 插件:xpath-helper
 尝试调整一下xpath ,让插件获取到最近100期的数据:
尝试调整一下xpath ,让插件获取到最近100期的数据: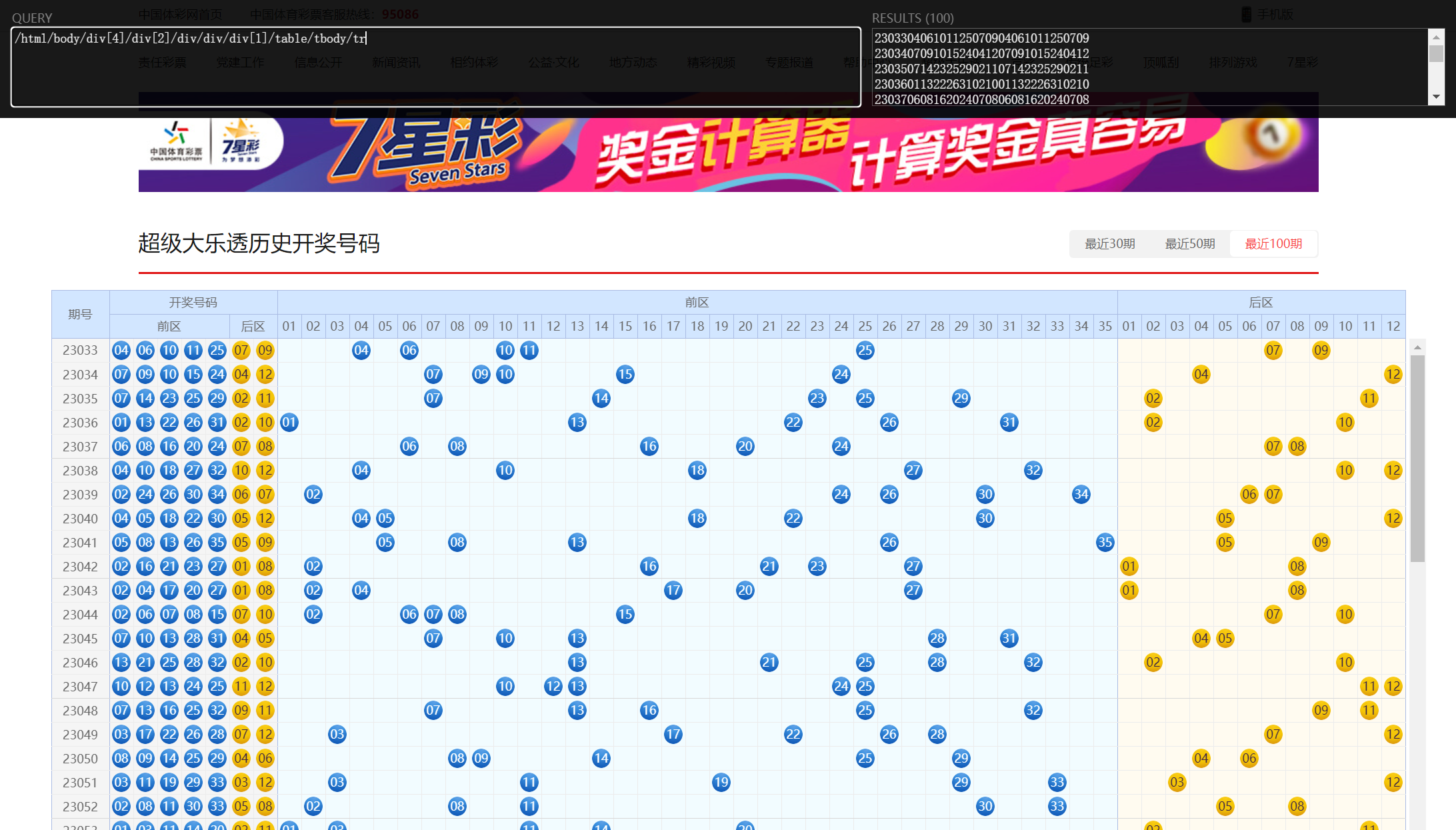 把图中
把图中